Why this Post?
When founding Verbyx in 2011, I found that although I understood the business and application of Automatic Speech Recognition (ASR) very well. Understanding speech recognition and the workings of an ASR required some work. I wanted to remedy that situation. Once again, during my learning journey, I found it to be a topic that was presented either very simply or at the other end of the scale, required advanced knowledge of math and physics. In this article I answer the question, how does an ASR system work?
Disclaimer
Understanding speech recognition is difficult. There are many ways of implementing speech recognition processes. In this article, I have focused on the traditional and most common method that uses Gaussian Mixture Models and Hidden Markov Models (GMM-HMM). There are also many ways of implementing GMM-HMM systems, this article describes only one. Finally, many of the concepts have been greatly simplified for ease of understanding. Some steps may have been omitted as they add little value to the intent of the article. The first part of the article describes ASR in very basic conceptual steps. The remainder of the article explains the process and technology, but without I hope, going into excessive detail.
The Importance of Understanding Speech Recognition
Given the complexity of an ASR, understanding speech recognition is of value to those that may be tasked with its use. Know how an ASR system works can help with writing requirements for an ASR purchase, integrating with external applications, software testing, product management of speech-enabled systems, buying and program management. An understanding of speech recognition will help with the planning and budgeting of programs that use the technology. It is also important to help effectively communicate with your chosen ASR vendor.
ASR Components
In asking the question, how does speech recognition work, it is useful to understand the key components of an ASR. A speech recognition system is comprised of several key components:
The ASR (The recognizer, the decoder) – This component executes the actual task of recognition. The input is audio and the output is one or more (Called N-Best) recognition hypothesis and an interpretation of the actions to be executed by the attached simulation device.
The language model (grammar and dictionary) – The language model contains a list of all phrases the ASR is expected to recognize. The dictionary is a phonetic representation of the words that make up the supported phrases.
The acoustic model – This component provides the ASR with a model of the speaking characteristics of the target user, e.g., US English. A system that uses a US English acoustic model will not perform as well for a French-accented English speaker.
The Conceptual ASR Process
Explaining how an ASR system works is complex. Prior to understanding how an ASR system works, let’s look at the basic concepts. ASR turns audio into text by analyzing a digital representation of small pieces of the audio called phonemes. A phoneme is the smallest unit of sound that may cause a change of meaning within a language, but that doesn’t have a meaning by itself. A widely used phoneme set is the ARPABET set that contains 39 phonemes. The number of phonemes is dependent on your chosen set. The phoneme set being used is dictated by the target language.
The phoneme set is used by linguists to define how words are spoken:
Phoneme Example Translation
AA odd AA D
AE at AE T
AH hut HH AH T
AO ought AO T
AW cow K AW
AY hide HH AY D
The translation column above is called the lexicon or dictionary. Given factors such as speaker accents, it is common to find many different phonetic descriptions of a single word, e.g., “button” may be pronounced “butn” by some speakers.
Phoneme Recognition
The ASR decoder takes the first piece of audio (in numeric form) and compares it against all possible phonemes (also described numerically). Later in this explanation, we will describe how the ASR uses smaller pieces of audio (phoneme states) that when combined make up the actual sound of the phoneme, but for now, we will assume the phoneme is the smallest unit.
This first phoneme in the sequence would be from a list of unique phonemes as contained in the phoneme set and determined by the language model. It is possible that some phonemes are not being searched at the start of the process. This will happen if the phoneme does not appear as the first phoneme of at least one of the words in the dictionary. The ASR scores the likelihood of each of those phonemes being spoken. Not all phonemes will pass muster and the ones that do not are dropped from the search. The next step takes the next segment of audio and looks for the next possible phoneme in the sequence. If one of the valid options in the first step was the phoneme AA, the search would be restricted to only the phonemes that follow AA as defined by the dictionary described above.
For the AA phoneme, there may be for example 25 possible following phonemes. The same process is used for each of the valid phonemes from step 1. This process is repeated until a list of probable words and their scores are generated.
You should see from this explanation that the ASR is not just processing one search path, but it is, in fact, processing multiple search paths simultaneously. How the ASR handles many paths will be discussed later.
Word Recognition
After analyzing several segments of audio, we will start to recognize complete words. When we recognize a possible word, we will add another search path to look for the next word in the sentence. The original search path is retained and continues because it is possible that the word, we have recognized is a part of a longer word, e.g., think and thinking.
When searching for the next word, we follow the same process as we did when searching for the phonemes, i.e., we start comparing the audio with the first phoneme of all of the possible words that can follow the first word (we are also looking for the representation of silence which can appear between words). Given that there are roughly 200,000 words in the English language, we can improve the likelihood of finding the correct next word by restricting our search to only words that are likely, e.g., the two words “the dog” is more likely than “dog the”. This is handled by the language model.
The language model in a GMM-HMM system is either a statistical model or a constrained grammar model. A statistical model uses statistical probabilities to determine the likelihood of one word following another word (again not completely accurate but it will do for now). It is generated by processing large volumes of text to compute the statistics. A constrained grammar model uses explicitly defined sentences to dictate word order.
This recognition process continues until the end of the last piece of audio. Throughout the process, the ASR is computing scores to determine the probabilities of phonemes following phonemes and words following words. It is repeatedly eliminating phonemes and words as higher scoring possibilities are calculated (this is called pruning). The output from the ASR will be one or more possible strings of text. Typically, the top score will represent the correct representation, however, it is possible that a lower scoring result is correct.
You have taken the first steps in understanding speech recognition. The remainder of the post will discuss the topic in more detail.
How Does an ASR System Work?, with More Detail
Preparing the Audio
The first step in understanding speech recognition is to look at the first step of the speech recognition process is to convert analog audio to digital. This is done by the microphone.
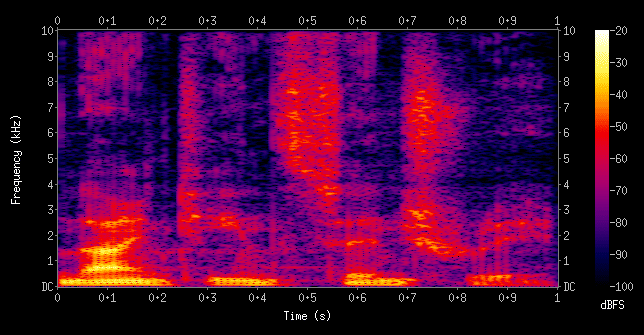
An algorithm called Fast Fourier Transform (FFT) is used to create a spectrogram of the audio.

The spectrogram is a visual representation of a frequency spectrum. It is a deconstruction of the frequencies that comprise the source audio. It is depicted in segments called frames. These frames are approximately 25ms each and contain not only the frequency information but the energy (volume) contained in the signal, and this energy represented in the spectrogram by colors. The frames are of a consistent size, but each frame contains information from overlapping windows of the digital audio. The window moves along the timeline in 10ms intervals. A 25ms (0.025s) window, with 8KHz sample rate audio, is equivalent to 200 audio samples (0.025 seconds * 8000 samples/second).
A 10ms (0.01s) step, is equivalent to 80 samples.
So, the first frame, which gives us feature vector X0, is from audio sample 0 to 199.
The second frame, which gives us feature vector X1, is from audio sample 80 to 279,
etc. until reaching the end of the audio.
A vector, in this case, is a series of numbers. This will be described in more detail later in the article.
The frames represent smaller pieces of each phoneme called phoneme states. A common number of phonemes states is 3 but more can be used. Verbyx VRX for example often uses a 5-state model. Each frame represents 1 state of 1 phoneme. A single phoneme will be represented by more than 1 frame.
We transform the information in each frame into a set of features called a vector (a list of numbers). This is done using Mel Frequency Cepstral Coefficient (MFCC). The actual workings of MFCC is one of those topics that is not suited to this article. If you are interested in learning more, an excellent article can be found here https://bit.ly/2tdCzvx
MFCC produces 12 values from the frequency spectrum and energy value. An additional 13 features are derived that represents how the initial 13 values are changing over time. So, 13 delta values are added (rate of change, aka velocity) by looking at previous and next frames and another 13 delta-delta values (rate of change of the deltas, aka acceleration) by looking at pairs of past and future frames. This gives us our 39 MFCC based features. This is 39 features for each state of each phoneme.
Prior to Decoding – Training the Acoustic Model
For additional information on the importance acoustic model please refer to this post. What is an Acoustic Model and Why You Should Care?
An ASR system decoder requires two additional components to assist in solving the puzzle, a language model which represents the construction of words and sentences, and an acoustic model which is a mathematical representation of how we speak.
Training an acoustic model requires audio samples and associated text transcripts for each audio utterance. The audio samples are converted into frames using the process described earlier. A process called forced alignment uses the transcript as a reference, to identify for each frame, what phoneme state is contained within that frame. It also identifies boundaries between phonemes and words.
When training we are building models of two components, the context-independent (Ci) model, i.e., single phonemes and the Context-Dependent (Cd) model, typically 3 phonemes together, a triphone. The CD model considers the impact of the prior phoneme and the following phoneme on the feature vector for the center phoneme of the three, i.e., the impacts of the earlier phoneme and the following phoneme will produce a different set of numbers for the vector of the center phoneme.
To create a Ci model, we group the vectors generated from the training audio, for each state of each phoneme, i.e., everywhere we experience State 1 of the AA phoneme it is grouped. The vectors for each of these training samples differ. This is because of the variation in speakers. Slow speakers, fast speakers, women, men, children, etc. Remember for each 25ms we have a vector that contains 39 features (or numbers). Given that the accuracy of our ASR improves as we increase the amount of training audio, we might be looking at many thousands of hours of samples.
The group of vectors (39 numbers or 39 dimensions) for each state of each phoneme produces several Gaussians, which are distribution models of that information. The number of Gaussians is determined by the person training the model and 8, 16, 32 and 64 Gaussians are common. Given the variation in speakers contained in the training audio, the purpose of the Gaussians can be conceptualized as a clustering of the vectors to be used later in the decoding process. Since conceptualizing 39 feature dimensions is incredibly difficult, let’s assume we have only 2 dimensions, an X and a Y. We plot those vectors and given speaker variations, we will see groups of similar vectors in one area of the plot and another grouping in another area of the plot. The number of Gaussians chosen determines how many clusters the algorithm will attempt to model.
An identical process is used to create a context-dependent model. In this case, we group the vectors where we find samples of a single phoneme state within identical triphones, i.e., every time the phoneme state for D, appeared in the center of Triphone AA D T it would be added to a group containing the same triphone structure. If D appeared in the Triphone T D AA, this would be a different group. We do this because the phoneme before and after the middle phoneme often affects how that center phoneme is spoken.
Before moving back to the decoding speech recognition process, let’s discuss the purpose of the Ci model. When decoding we are looking to identify triphones that when combined make words. If we do some simple math, we can see the size of this search problem is very large If I have 40 phonemes, the number of possible triphones is 40x40x40 = 64,000. Not all triphone combinations are valid and the dictionary will allow us to prune invalid combinations.
However, a technique called shared states eases the burden, i.e. we decide two states or more states from different tri-phones should be similar enough that we can combine the data and share the model (GMM).
As will be described later in the decoding description, for each frame of audio during the decoding phase, we must find, in the acoustic model (a massive list of numbers), every possible triphone for the sequence as guided by the language model. We then must take the vector for that frame and compute for every possible triphone in the sequence, a score for each state of each center phoneme for each of the possible 64 Gaussians in the acoustic model. The score is used to rate the most likely phoneme state for that frame.
All of that to say, this is a very large problem. Admittedly this is a much-simplified explanation and it does not detail techniques that reduce the problem, such as shared states, but it is good enough to grasp the difficulty of the recognition process.
Starting the search with the Ci model, we reduce the search problem to only 40 phonemes. This results in 120 phoneme states for a 3-state model. Compare this to the 192,000 triphone states in the Cd model. Given the exponential expansion of the problem when considering the number of Gaussians and 39-dimension vectors, the reduction is significant. The Ci process is materially faster than the Cd decoding process. At the end of a Ci decoding process, we will have quickly eliminated most of the phonemes in the phoneme set. We then use the invalid phonemes to eliminate all the corresponding invalid triphones, i.e., if the phoneme AA is not a valid phoneme, then AA T AE is not a valid triphone. We have significantly reduced the size of the triphone search problem.
How Does an ASR System Work, back to Decoding
The final steps in understanding speech recognition are to look at decoding. At the start of ASR decoding, we have the vector for the first frame of audio. The language model provides us with information we can use to determine what phone that frame contains (actually what piece of what phoneme or phoneme state). At the start of the process, every phoneme is a valid possibility for the first phoneme in a triphone, including the phoneme for silence. Once we have the first phoneme the words in the language model determine the next possible phoneme and so on.
We begin with the Ci process. We take the vector from the frame and we compute a score for that vector against each gaussian for each state of each valid phone. This score is a representation of how closely related this vector is to the mean value of each Gaussian. The closest Gaussian is the most likely match. Remember in this system a gaussian models a single state (piece) of a single phoneme.
A system parameter is used to eliminate unlikely results, e.g., every score below 50 gets dropped. We then begin the Cd process where the same steps are followed. The vector from the frame is used to calculate scores against the Gaussians for the center phone for the valid triphones. Remember we use the Ci to eliminate invalid triphones. Again, we use a parameter to eliminate low scoring triphones.
All valid triphones are used as the beginning of the decoding speech recognition process that results in multiple paths to a result.
The Ci process then begins again. Using the last phoneme of each triphone we recognized in the previous stage, the language model gives us a list of possible next phones in the word we are trying to recognize. We compute scores, eliminate phones, and move on to the Cd process where we do the same thing. As we move through the process we begin to form words and then sequences of words. There will be many simultaneous paths each containing possible solutions.
The scores generated in the decoding process are combined, with the highest score being the most likely result. It is necessary as the process continues to reduce the number of search paths. This is done for memory management and speed of processing. The method used is called pruning. A value called the beam width determines when a path is dropped. It may not be the entire path that is dropped due to shared branches. E.g.,
Path1 – The cat sat on the mat
Path 2 – The cat sat on the cat
Both paths share a common set of words, i.e., “the cat sat on the”. If path one scores below the beam width setting and path one has scored above the setting, only path two is dropped.
At the end of the utterance, the decoder generates several possible results (N-Best) each with a score. The highest score is the most likely result. It is up to the user to determine how to choose from this list. The ways this might be done are for another discussion.
Summary
Even with this very basic description, it is easy to see how challenging understanding speech recognition is. You can also clearly see the importance of the acoustic model and the language model to the result. I hope this article has helped you on your path to better understanding speech recognition and how it works.