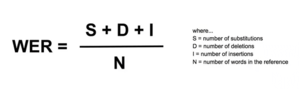Word Error Rates are Misleading
The system must have a Word Error Rate (WER) of 2% or less. This appears to be a reasonable requirement. With such a small error rate, surely, I can be confident that my speech recognition implementation will be a success?
Unfortunately, the answer is no for simulation or command and control applications. This post discusses why Word Error Rates are misleading and are not a good measure of the usability of a speech system.
Testing Method
Prior to automated testing for WER, some preparation is necessary. Accurate transcription of the audio is the first requirement. To clean the data, the removal of poor quality audio and utterances that contain unsupported phrases is required. A comparison of the transcriptions and the hypothesis (ASR result) are made to identify errors. For the generation of meaningful test results a large test set, with a broad range of speakers, is vital. The data includes male and female speakers with a range of accents that represent the target users.
Customer testing usually includes a free-play test phase. After free-play, the same scoring method is used; however, in this case, the audio has not previously been transcribed. The contract may also allow the vendor to remove the audio utterances from certain speakers that have a difficult speaking style.

Ideal Test Conditions
So word error rate is an excellent measure of the performance of ASR when using supported terminology with approved speakers. But the impact of using ASR with non-approved speakers must be considered, that is speakers not familiar with the strict approved terminology (trainees) in less than ideal circumstances. This is an issue we will tackle in a future post. For now, we will continue to examine word errors.
Why are WER Not a Good Measure
If the test data contained 10,000 words and our error rate was 2% then we have 200 words that were incorrect. This does not seem to be a major hurdle, but consider an application where numbers are critical and a common occurrence, such as a flight simulator:
“American one one three five, heading two three zero and descending to three thousand.”
If on examination we find that the errors are with words such as “and”, in the example above it is likely we will still achieve the correct semantic match. If the majority of the two hundred errors are the word three, we now have an unusable system.
So if you can’t rely upon WER, how can you specify your accuracy requirements? This free download Speech Recognition Requirements provides further guidance on this topic and defining speech recognition requirements